Welcome back! In this lesson, we will explore an improved version of the k-means clustering algorithm: mini-batch k-means. This variant is designed to speed up the clustering process, especially when working with large datasets, while still producing high-quality clusters. We will discuss the mini-batch concept and implement the algorithm step by step using C++.
In clustering, a mini-batch refers to a small, randomly selected subset of the data that is used in each iteration of the algorithm. Instead of using the entire dataset to update the cluster centers at every step, mini-batch k-means uses only a small batch of data points. This approach greatly improves computational efficiency and allows the algorithm to scale to larger datasets.
Before implementing mini-batch k-means, we need to generate a dataset and define some helper functions. In this example, we will create two clusters of 2D points using random number generation in C++. We will also define functions to compute the Euclidean distance and to randomly initialize cluster centers.
Here is how you can set up the data and helper functions in C++:
To generate the dataset, we use normal distributions to create two distinct clusters:
Now, let's implement the mini-batch k-means algorithm in C++. The algorithm works as follows:
- Randomly initialize the cluster centers.
- For a fixed number of iterations:
- Randomly select a mini-batch of data points.
- Assign each point in the mini-batch to the nearest cluster center.
- Update each cluster center based on the mean of the points assigned to it in the mini-batch.
Here is the C++ implementation:
You can now run the algorithm on your generated data:
After running the mini-batch k-means algorithm, you will have the final cluster centers. To check the results, you can print the coordinates of the centers or visualize the clusters.
If you have a C++ plotting library such as matplotlibcpp, you can visualize the data and the cluster centers as follows:
Plot:
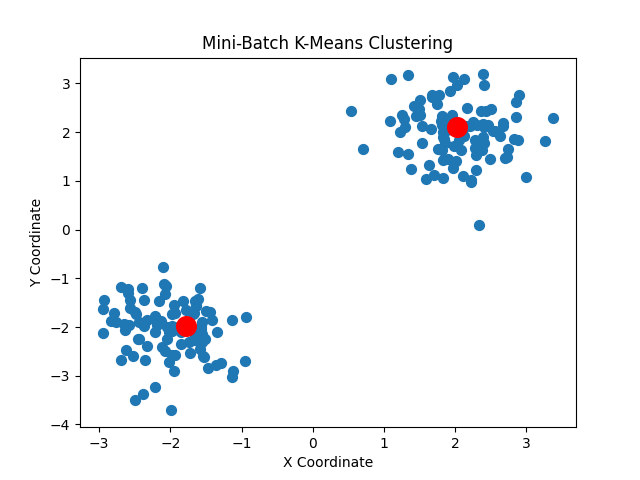
The mini-batch k-means algorithm is a powerful tool for clustering large datasets. Its main advantage is computational speed, as it updates cluster centers using only a small subset of the data at each step. This makes it suitable for large-scale data mining tasks where time and resources are limited. However, the results may be less precise than those obtained with the classic k-means algorithm, since not all data points are used in every iteration.
In this lesson, you learned about the mini-batch k-means algorithm and how to implement it in C++. You saw how mini-batches can make clustering much faster, especially for large datasets. Try experimenting with different parameters, such as the number of clusters, batch size, and number of iterations, to see how they affect the clustering results. Practicing these concepts will help you gain a deeper understanding of clustering and its applications.
