Psychological safety gives the team room to disagree. Talent decisions are where that room gets tested most quietly, because the bias that shaped last quarter's stretch assignments was probably never spoken out loud. This unit gives you a structured way to make those calls, advocate for the candidate who'd otherwise be missed, and deliver the no without rebuilding the bias on the way out.
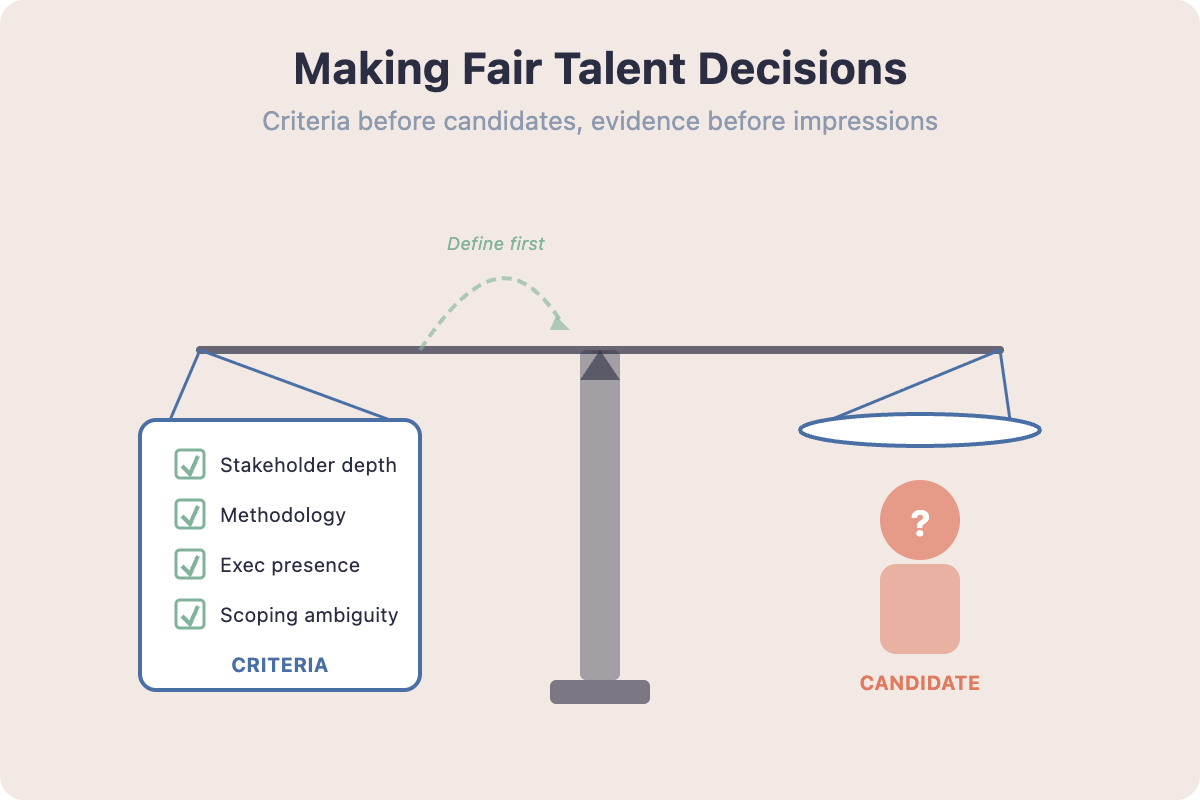 The default move when a stretch opens is to picture your two strongest reports and ask "who's more ready?" That question is almost always answered by recency, halo, or affinity, because "ready" has no fixed definition. The fix is the Structured Talent Decision Rubric: Define role-relevant criteria, Collect evidence, Rate consistently, Calibrate differences, Document rationale, Communicate development support.
The default move when a stretch opens is to picture your two strongest reports and ask "who's more ready?" That question is almost always answered by recency, halo, or affinity, because "ready" has no fixed definition. The fix is the Structured Talent Decision Rubric: Define role-relevant criteria, Collect evidence, Rate consistently, Calibrate differences, Document rationale, Communicate development support.
The first step does most of the work. Before you look at people, look at the role. What does this stretch actually demand? For a six-month customer-segmentation lead, the criteria might be stakeholder management across three orgs, segmentation depth, comfort presenting unfinished work to execs, and the ability to set scope under ambiguity. Four to six criteria, no more. If "executive presence" makes the list, define it observably ("can hold a room when an exec pushes back on the analysis") or take it off, because undefined criteria are bias on a leash.
Then collect evidence per criterion per candidate. Not impressions, moments. "Handled the legal pushback solo in week three of the pricing project" is evidence. "Has good judgment" is a halo. Rate both candidates on the same scale before you compare them, so the bar doesn't drift to fit a preferred name. Document the rationale, not for HR, but for yourself in six months when you're tempted to forget which call was made on evidence and which was made on vibes.
Calibrations are where the rubric earns its rent. You'll walk in with a candidate who's strong on the criteria but lower on visibility, and a peer will walk in with a polished candidate they've seen in the room with the VP. The temptation is to argue the candidates. Don't. Argue the criteria first.
- Ryan: I think we have to go with my person, he's been in the room with the VP, the polish is there.
- Nova: Before we land there, what are we actually optimizing this role for? I had stakeholder depth and methodology at the top.
- Ryan: Sure, but executive presence matters too.
- Nova: Agreed. How do we tell it from visibility? Mine led the legal pushback solo in March. What evidence do we have on yours in that kind of moment?
- Ryan: Honestly, I haven't seen him in that exact situation.
- Nova: Then let's separate what we have evidence for from what we're inferring.
Notice Nova didn't attack the peer's candidate or accuse anyone of bias. She pulled the criteria into the open, asked what evidence existed for the proxy, and offered a concrete moment for her own candidate. The win condition isn't selecting your person; it's making sure whoever is selected is selected on the criteria. If the peer can articulate a real, evidence-based gap, that's a useful outcome. If they can only articulate a visibility gap, the conversation has done its job.
The last step of the rubric is the one most managers fumble: Communicate development support. The report who wasn't picked is reading your delivery for two things, whether you're being straight with them, and whether you'll still back them. Pad the criteria where they were strong and they'll hear it as managing; hide behind "the group decided" and they'll hear it as cowardice.
Lead with the decision plainly: they weren't selected. Name the one or two specific criteria where the gap was, using the same language from your rubric, and reference a moment, not a feeling. Don't list the criteria where they were strong as consolation; it reads as filler. Then offer two specific development moves you'll back this quarter: a named cross-functional exposure, a visibility moment, a stretch piece of an upcoming project. Concrete commitments, not "next time." Stay with their disappointment. Silence is fine. The things you don't say: "it was political" or "someone else pushed harder for their person." Blaming the room rebuilds the unfairness you just tried to interrupt.
This is where it gets concrete. The takeaway is sharp: fair talent decisions are made by criteria before candidates, defended in calibration by evidence not loyalty, and delivered with specificity not softness. Three practices sit ahead. First, a quick check on whether you can spot the comparison approach that actually applies the rubric versus the ones that smuggle bias back in. Then a calibration where a confident peer is leaning on visibility proxies and you have to shift the frame without picking a fight. Finally, the harder one: the 1:1 where your direct report walks in hopeful and the next sentence you say decides whether they leave with a real plan or a rehearsed reassurance.
