Introduction to LDA and Its Role in Supervised Learning
Welcome to the world of Linear Discriminant Analysis (LDA), a technique widely used for dimensionality reduction in supervised learning. In this lesson, we'll explore the concepts behind LDA and build an implementation from scratch using R. For our practical example, we'll use the classic Iris dataset, a well-known dataset in R, to demonstrate how LDA works in practice.
Understanding the Algorithm of LDA
LDA reduces dimensionality by constructing a feature space that optimally separates the classes in the data. The axes in this space are linear combinations of the original features and are known as eigenvectors. The LDA algorithm consists of several steps, such as calculating class mean vectors and scatter matrices, then finding eigenvalues and eigenvectors that map the original feature space onto a lower-dimensional space.
The Inner Workings of LDA: Mathematics and Intuition
To understand LDA, let's start with a simple two-dimensional example. Suppose we have data points scattered across a 2-D space, with each point belonging to one of two possible classes.
In LDA, we want to project these points onto a line such that, when the points are projected, the two classes are as separated as possible. The goal here is twofold:
Maximize the distance between the means of the two classes.
Minimize the variation (in other words, the scatter) within each category.
This forms the intuition behind LDA. The crux of an LDA transformation involves formulating a weight matrix and transforming our input data by multiplying it with this weight matrix. The weights here help increase class separability. Let's see how we can achieve this mathematically using scatter matrices.
Scatter Matrices: Capturing Variability
The LDA Algorithm: A Step-by-Step Breakdown
Preparing the data for LDA
Let's load the Iris dataset for LDA, which is a 3-class dataset with 4 features. In this example, we'll rename the features to weight_lbs, weight_kgs, and height for demonstration purposes.
# Load required librarieslibrary(ggplot2)library(dplyr)# Load the iris datasetdata(iris)# Rename features for demonstrationcolnames(iris)[1:3] <- c("weight_lbs", "weight_kgs", "height")# Extract features and targetX <- as.matrix(iris[, c("weight_lbs", "weight_kgs", "height", "Petal.Width")])y <- as.numeric(iris$Species)
Should You Scale Data for LDA?
Before proceeding, it's important to consider whether to scale your data for LDA. LDA makes the assumption that each class shares the same covariance structure, and the method is sensitive to the scale of the input features. If your features are measured in different units or have very different variances, those with larger scales can dominate the computation of scatter matrices and the resulting discriminant directions. This can lead to misleading results, as LDA may focus on the features with the largest variances rather than those that best separate the classes.
When to scale:
If your features are on very different scales (e.g., height in centimeters and weight in kilograms), scaling is recommended.
If all features are already on a similar scale, scaling may not be necessary.
How to scale:
A common approach is to standardize each feature to have zero mean and unit variance. This ensures that each feature contributes equally to the analysis, and the LDA solution is not biased toward features with larger variances.
Let's standardize the features in our example:
# Normalize the data to zero mean and unit varianceX <- scale(X)
By scaling the data, we help ensure that LDA's assumptions are more closely met and that the resulting discriminant axes are not unduly influenced by the scale of any particular feature.
Building Simple LDA from Scratch - Part 1: Defining the LDA Structure
In R, instead of classes, we typically use lists and functions to encapsulate model state and behavior. We'll define a list to hold the transformation matrix and functions to perform the LDA steps.
LDA <- list()LDA$W <- NULL
Here, LDA is a list that will store the transformation matrix W after fitting the model.
Part 2: Computing Within-class Scatter Matrix
Part 3: Computing Between-class Scatter Matrix
Part 4: Eigenvalues, Eigenvectors, and Subspace Transformation
Transforming the Samples onto the new Subspace
Next, we fit the LDA model, transform the data, and plot the projected samples using ggplot2. We'll use the first two components for visualization.
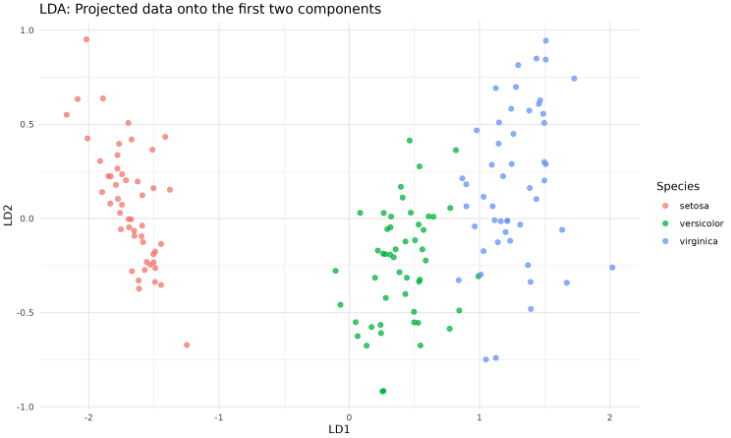
# Fit LDA and transform datan_components <- 2W <- fit_lda(X, y, n_components)X_lda <- transform_lda(X, W)# Prepare data for plottinglda_df <- data.frame( LD1 = X_lda[, 1], LD2 = X_lda[, 2], Species = iris$Species)# Plot the transformed dataggplot(lda_df, aes(x = LD1, y = LD2, color = Species)) + geom_point(size = 2, alpha = 0.7) + labs( title = "LDA: Projected data onto the first two components", x = "LD1", y = "LD2" ) + theme_minimal() + theme( panel.background = element_rect(fill = "white", color = NA), plot.background = element_rect(fill = "white", color = NA) )
The output will look like this:
This code creates a scatter plot of the data projected onto the first two linear discriminants, colored by species.
Lesson Summary and Upcoming Practice
Great job! You've successfully understood the concepts of LDA and its mathematical foundation, and built a simple LDA from scratch using R. Now, get ready for practice exercises to apply your newly acquired knowledge and consolidate your learning! Happy learning!
Be a part of our community of 1M+ users who develop and demonstrate their skills on CodeSignal
Scatter matrices are a critical part of LDA. To understand them, we need to differentiate between two types of scatter matrices:
The within-class scatter matrix measures the variability of data points within each class.
The between-class scatter matrix captures the variability between different classes.
Mathematically, the within-class scatter matrix SW is computed as the sum of scatter matrices for each class, and the between-class scatter matrix SB is calculated based on the means of different classes.
Given the mathematical foundations of within-class and between-class scatter matrices, the steps involved in the LDA algorithm can be conceptualized as:
Compute class means: Calculate the average value for each class.
Compute the within-class scatter matrix SW.
Compute the weights that maximize separability: This is obtained by multiplying the inverse of SW and the difference between the class means.
Use the weights to transform our input data.
Let's translate this into R code.
R
# Load required librarieslibrary(ggplot2)library(dplyr)# Load the iris datasetdata(iris)# Rename features for demonstrationcolnames(iris)[1:3] <- c("weight_lbs", "weight_kgs", "height")# Extract features and targetX <- as.matrix(iris[, c("weight_lbs", "weight_kgs", "height", "Petal.Width")])y <- as.numeric(iris$Species)
R
# Normalize the data to zero mean and unit varianceX <- scale(X)
R
LDA <- list()LDA$W <- NULL
The within-class scatter matrix is a crucial component in the LDA algorithm — it encapsulates the total scatter within each class. To calculate it, we first define the scatter matrix for each class, and then add them all to give us the within-class scatter matrix, SW.
Mathematically, the scatter matrix for a specific class is computed via:
SW=Σi=1gΣj=1Ni(xij−m)(xij−m)T
Here is how you can compute the within-class scatter matrix in R:
This function computes the within-class scatter matrix, which measures how spread out individual class instances are around the mean. This matrix helps LDA understand the overall structure of classes within our data.
The between-class scatter matrix captures the variance between different classes. It is calculated as follows:
SB=Σi=1gNi(mi−m)(mi−m)T
Here is how you can compute the between-class scatter matrix in R:
This function measures how far the mean vector of each class is from the mean vector of the whole dataset, capturing the 'distance' between different classes.
Now that we've calculated the scatter matrices, we can write a function to fit the LDA model. This function finds the generalized eigenvalues and corresponding eigenvectors, and selects a subset for transformation.
R
fit_lda <- function(X, y, n_components) { S_W <- within_class_scatter_matrix(X, y) S_B <- between_class_scatter_matrix(X, y) # Solve the generalized eigenvalue problem eig <- eigen(solve(S_W) %*% S_B) eig_vals <- eig$values eig_vecs <- eig$vectors # Sort eigenvectors by eigenvalues in descending order eig_pairs <- lapply(1:length(eig_vals), function(i) list(value = abs(eig_vals[i]), vector = eig_vecs[, i])) eig_pairs <- eig_pairs[order(sapply(eig_pairs, function(x) -x$value))] # Form the transformation matrix W W <- do.call(cbind, lapply(1:n_components, function(i) eig_pairs[[i]]$vector)) return(W)}
The function above computes the eigenvalues and eigenvectors of the matrix SW−1SB, sorts them by eigenvalue, and selects the top n_components eigenvectors to form the transformation matrix W.