Before we dive into tuning tree depth, let’s quickly review what a decision tree is. A decision tree is a type of machine learning model that makes predictions by learning a series of simple decision rules from the data. You can think of it like a flowchart: at each step (or “node”), the tree asks a question about one of the features (for example, “Is the fruit red?”). Based on the answer, it follows a branch to the next question, and so on, until it reaches a final decision at a “leaf” node (for example, “This is an apple”).
Decision trees are popular because they are easy to understand and interpret. Each path from the root to a leaf represents a sequence of decisions that leads to a prediction. However, if the tree is allowed to grow too deep, it can become very complex and start to memorize the training data instead of learning general patterns. That’s why controlling the depth of the tree is important, which is what we’ll focus on in this lesson.
Welcome back! In the last lesson, you learned how to control the complexity of a logistic regression model using L2 regularization and the C parameter. You saw how tuning this parameter helps you find the right balance between underfitting and overfitting. In this lesson, we will look at a different type of model — decision trees — and see how you can control their complexity using a parameter called tree depth.
To help you visualize, here’s a simple example of a decision tree that predicts whether a fruit is an apple or not:
In this tree, the model first checks if the fruit is red. If yes, it checks if the weight is greater than 150g. Based on the answers, it predicts whether the fruit is an apple or not. This tree has a depth of 2, since the longest path from the root to a leaf has two decisions.
Tree depth is a simple but powerful way to manage how much a decision tree can learn from your data. Just like with regularization in logistic regression, setting the right tree depth is important for achieving good performance. If the tree is too simple, it might miss important patterns. If it is too complex, it might memorize the training data and not work well on new data. By the end of this lesson, you will know how to train decision trees with different depths and how to spot when your model is underfitting or overfitting.
Let’s take a moment to remind ourselves what overfitting and underfitting mean, but now in the context of decision trees. Imagine you are trying to teach a friend how to recognize different types of fruit. If you only give them a few simple rules, like “if it’s red, it’s an apple,” they might miss out on other fruits that are also red. This is like a decision tree with very shallow depth — it is too simple and underfits the data.
On the other hand, if you give your friend a huge list of very specific rules, like “if it’s red and weighs exactly 150 grams and has a stem that is 2 cm long, it’s an apple,” they might do well on the examples you gave them but struggle with new fruits they haven’t seen before. This is like a very deep decision tree — it memorizes the training data and overfits but does not generalize well.
The depth of a decision tree controls how many decisions (or splits) the tree can make from the root to a leaf. A shallow tree (low depth) makes only a few splits, while a deep tree can make many. Finding the right depth helps your model learn enough from the data without memorizing it.
Let’s see how this works in practice. Below is a code example that trains decision trees with different depths using scikit-learn’s DecisionTreeClassifier. For each depth, we measure the accuracy on both the training and test sets. This will help you see how tree depth affects underfitting and overfitting.
When you run this code, you will see a table like the following (the exact numbers will depend on your data):
In this table, each row shows the tree depth, the training accuracy, and the test accuracy for that model. As the depth increases, you will usually see the training accuracy go up, sometimes reaching 1.0 (perfect accuracy). However, the test accuracy may stop improving and even start to drop if the tree becomes too deep. This is a sign of overfitting.
Below is a visualization of this effect. The plot shows how training and test accuracy change as you increase the tree depth. Notice how the training accuracy keeps increasing, while the test accuracy peaks and then starts to decline as the tree gets deeper:
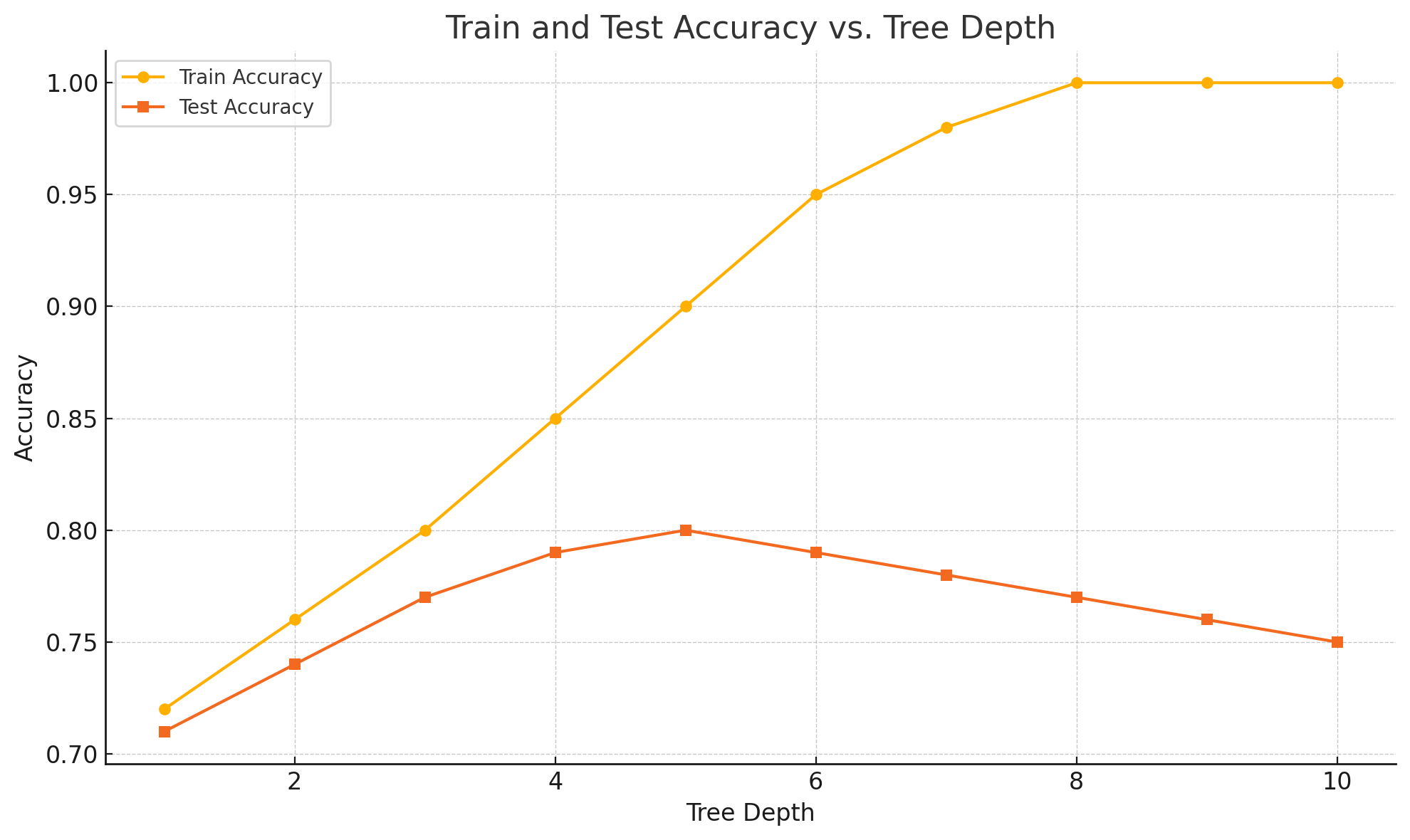
In this lesson, you learned what a decision tree is and how to control its complexity using the tree depth parameter. You saw that shallow trees can underfit the data, while very deep trees can overfit. By training trees with different depths and comparing their training and test accuracy, you can find a good balance that helps your model generalize well to new data.
Next, you will get a chance to practice tuning the depth of decision trees yourself. You will experiment with different values, observe how your model’s performance changes, and learn how to pick the best depth for your data. This hands-on practice will help you build strong intuition for model complexity and regularization in decision trees.
