Welcome to the fourth lesson in Deconstructing the Transformer Architecture! We've reached a pivotal moment in our journey where theory meets practice, and individual components unite to form something greater than the sum of their parts. Over the past three lessons, you've mastered the intricate mechanics of multi-head attention, understood the crucial role of feed-forward networks and Add & Norm operations, and discovered how positional encodings inject sequence awareness into these powerful models.
Now comes the exciting challenge: assembling these components into a complete TransformerEncoderLayer. If our previous lessons were about understanding the instruments in an orchestra, today we're conducting the symphony. We'll explore not just what goes where, but why the specific ordering of operations matters, how data flows through the encoder, and what makes this architecture so remarkably effective at learning complex patterns. By the end of this lesson, you'll have built a fully functional encoder layer and will understand the elegant choreography that makes modern language models possible. Let's dive in!
The Transformer encoder layer isn't just a stack of components: it's a carefully choreographed sequence of transformations that turns simple token embeddings into rich, contextually aware representations. Understanding this choreography requires appreciating a fundamental design principle: the encoder alternates between global reasoning (through attention) and local computation (through feed-forward networks), with each operation wrapped in mechanisms that ensure stable, efficient learning. Let's take a look at the architecture diagram (image taken from the original "Attention is all you need" paper):
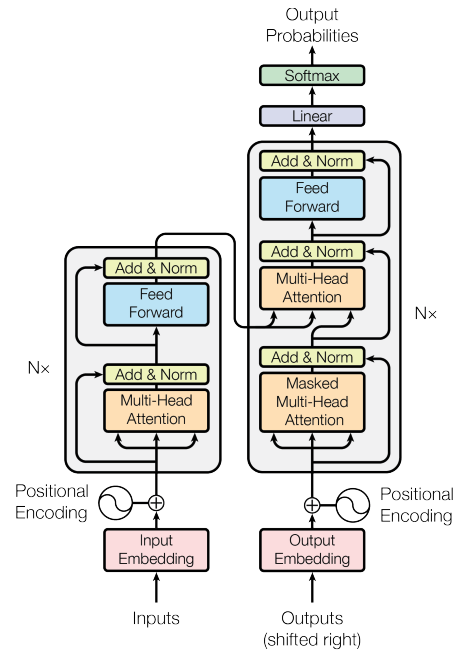
The magic happens through a precise order of operations: input embeddings first pass through multi-head self-attention, where each token can gather information from every other token in the sequence. This global information exchange is immediately followed by a residual connection and layer normalization, creating what we call the first sub-layer. The partially transformed representations then flow through position-wise feed-forward networks that process each position independently, applying non-linear transformations to extract higher-level features. Again, this is wrapped with residual connections and normalization as the second sub-layer.
Why this specific order? Attention must come first because it establishes the contextual relationships that the feed-forward network will then process. The residual connections ensure that no information is lost during transformation — crucial for deep networks where gradients might otherwise vanish. Layer normalization after each sub-layer keeps the activations in a stable range, preventing the exploding or vanishing gradient problems that plagued earlier deep architectures. This design pattern, repeated across multiple encoder layers, creates a powerful learning machine capable of capturing everything from simple word associations to complex semantic relationships.
Let's start constructing our TransformerEncoderLayer by establishing its core structure and understanding how our previously built components come together:
This initialization reveals the encoder layer's elegant simplicity: just four components working in harmony. The MultiHeadAttention module we built earlier handles the complex task of computing relationships between all token pairs simultaneously. The PositionwiseFeedForward network provides the non-linear processing power that transforms these relationships into useful features. What's particularly important is that we create two separate AddNorm instances. Each maintains its own layer normalization parameters, allowing the model to learn different normalization strategies for attention outputs versus feed-forward outputs — a subtle but crucial detail that improves training stability and model performance.
The parameter choices here matter too: d_ff is typically set to four times d_model in standard Transformers, creating an expansion-compression pattern in the feed-forward network that has proven effective across many tasks. The activation parameter lets us choose between ReLU (traditional) and GELU (often preferred in modern models), while dropout provides regularization at multiple points throughout the layer.
Now let's implement the forward pass that brings our encoder layer to life, starting with the critical first sub-layer:
This seemingly simple code encodes a profound insight about self-attention: by passing the same tensor x as query, key, and value, we enable each token to attend to all positions in the sequence, including itself. This is what distinguishes self-attention from cross-attention (where queries come from one sequence and keys/values from another). The attention mechanism returns both the transformed representations and the attention weights — the latter being invaluable for understanding what the model has learned.
The add_norm1 operation implements the crucial residual connection pattern. It takes the original input x and the attention output, adds them together, then applies layer normalization. This preserves the original information (through the residual) while stabilizing the scale of activations (through normalization). The mask parameter enables handling variable-length sequences or preventing attention to padding tokens — essential for real-world applications where sequences rarely have uniform length.
The second sub-layer completes the encoder's transformation pipeline:
After attention has enabled global information exchange, the feed-forward network processes each position independently. This "position-wise" processing is key: while attention creates a web of relationships across the sequence, the FFN extracts features from each enriched token representation separately. Think of it as first gathering context (attention), then processing that context locally (FFN). The typical pattern of expanding to a higher dimension (often 4x) then compressing back allows the network to learn complex non-linear transformations while maintaining the original representation size.
The second Add & Norm operation follows the same pattern as the first but with its own normalization parameters. This separation allows the model to adapt its normalization strategy based on the different statistical properties of attention versus feed-forward outputs. By returning both the final representations and attention weights, we enable both further processing by subsequent layers and interpretability analysis of what the model has learned to focus on.
Real Transformer power comes from stacking multiple encoder layers, each refining the representations from the previous layer:
Using nn.ModuleList ensures PyTorch properly tracks all parameters across layers for optimization and device management. Each layer in the stack has its own set of parameters, allowing different layers to specialize in different aspects of language understanding. Research has shown that lower layers often focus on syntactic features and local patterns, while higher layers capture more semantic and task-specific information.
The design choice to collect attention weights from all layers provides a window into the model's reasoning process. Different layers often exhibit distinct attention patterns: early layers might focus on adjacent words and syntactic relationships, while later layers can capture long-range semantic dependencies. This hierarchical processing is what enables Transformers to understand language at multiple levels of abstraction simultaneously.
Let's start by validating our TransformerEncoderLayer implementation to ensure it correctly handles the core transformation pipeline we've built:
Running this test produces the following output:
These results validate several critical aspects of our encoder layer: the transformation preserves input dimensions while creating rich internal representations, attention weights have the correct shape for 8 heads attending across all 10 sequence positions, and the masking functionality works correctly for handling padding tokens.
Now let's validate our full encoder implementation by testing it within a complete pipeline that mimics real-world usage:
This comprehensive test produces the following output:
The results confirm that our complete encoder implementation works seamlessly: raw token IDs are successfully transformed through the entire pipeline into rich contextual representations, the three-layer encoder stack produces three sets of attention weights as expected, and the final output maintains the correct dimensions while containing the hierarchical transformations from all encoder layers. This validates that our architectural components integrate perfectly to create a functioning Transformer encoder ready for downstream tasks.
We've successfully assembled a complete Transformer Encoder, witnessing how multi-head attention, feed-forward networks, and Add & Norm operations work in concert to create powerful sequence representations. The careful orchestration of these components — the specific ordering of operations, the systematic use of residual connections, and the hierarchical stacking of layers — reveals why the Transformer architecture has revolutionized natural language processing. Our implementation demonstrates not just the what but the why behind each design choice, from the alternation between global and local processing to the critical role of normalization in enabling deep architectures.
With our encoder complete, you now understand how Transformers build rich, contextual representations layer by layer, transforming simple token embeddings into sophisticated linguistic understanding. The upcoming practice section will give you hands-on experience with these concepts, so get ready to put your knowledge into action!
