Welcome to Compound Event Probability, the fourth and final course in this learning path! You have already built a strong foundation: you know what probability is, how to estimate it from data, and how to build probability models. Now we are going to bring all of that together and tackle events that involve more than one step.
In this first lesson, we will explore what compound events are, how they differ from the simple events we have worked with so far, and why finding their probabilities calls for a careful, organized approach. Let's get started!
Every probability question begins with an experiment (like rolling a die) and a sample space (the full list of possible outcomes). Up to this point, most of our experiments involved a single action — one coin flip, one spin of a spinner, or one draw from a bag. Those single-action experiments kept the sample space small and easy to list.
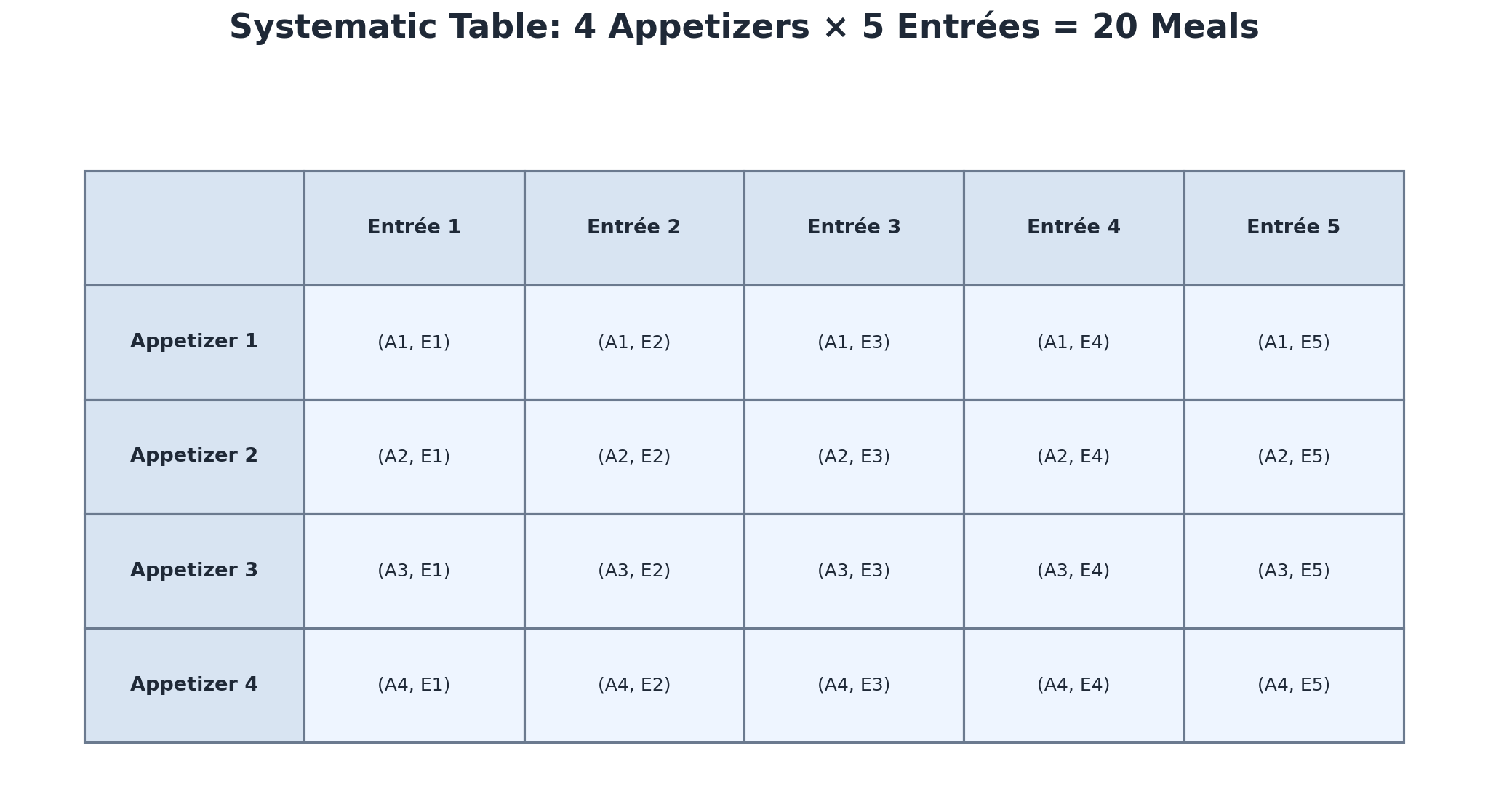
But everyday decisions rarely involve just one action. Think about getting dressed in the morning: you pick a shirt and then pick pants. Or consider ordering food at a restaurant: you choose an appetizer and an entrée. Each choice you make creates a new layer of possibilities that combines with the others.
That layered structure is exactly what separates compound events from the simpler events we have studied, and it is the focus of this entire course.
A simple event is the result of a single stage, trial, or experiment. There is only one action involved, so listing every possible outcome is straightforward. A compound event, on the other hand, combines two or more stages, trials, or experiments into a single situation. The outcomes of each stage pair together to form combined results.
In this lesson, we will focus on compound events made from independent stages, where the outcome of one stage does not affect the outcome of another. For example, flipping a coin does not change the result of rolling a die, and choosing a shirt does not affect the available pants.
The table below shows how the two types compare side by side:
Notice the key word "and" (or "and then"). Whenever an event involves multiple decisions or actions whose results pair up together, you are looking at a compound event. In this lesson, those combined stages are independent, which helps us count and organize the outcomes more clearly.
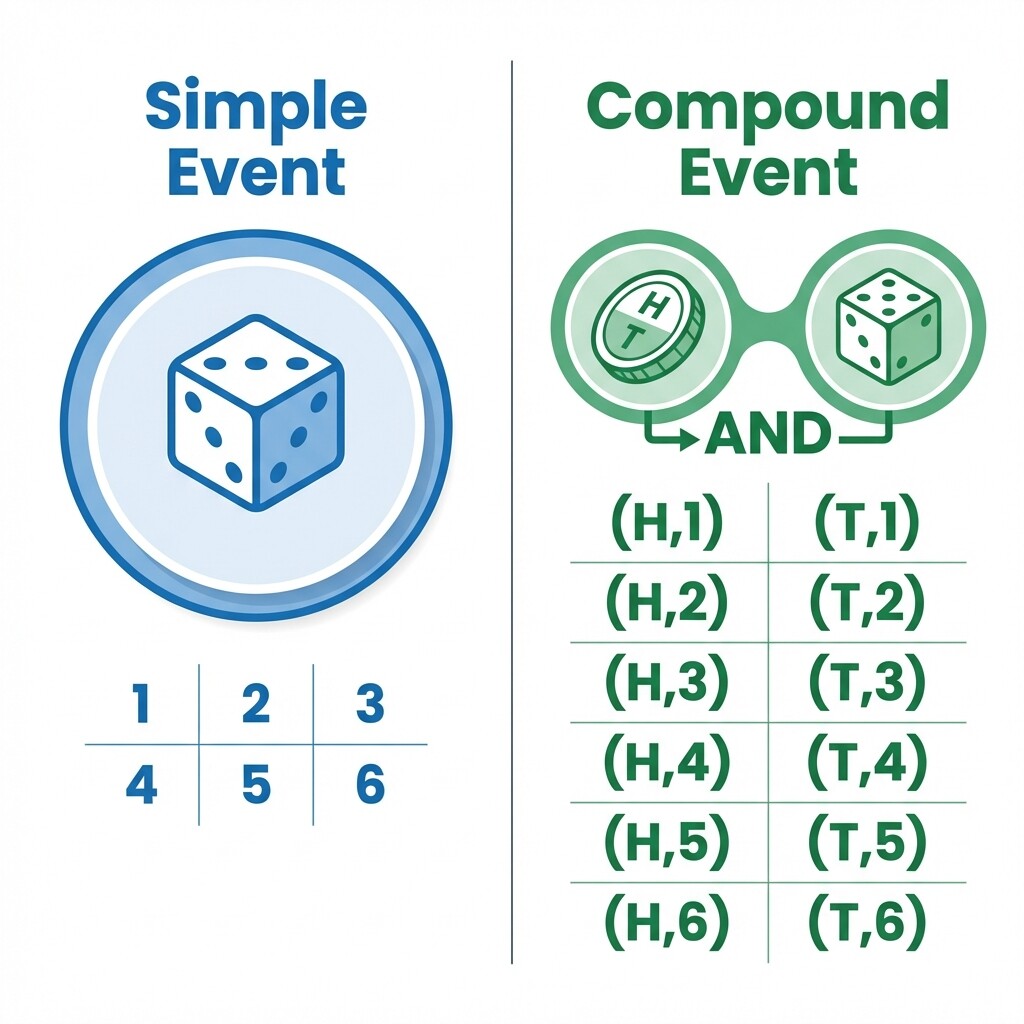
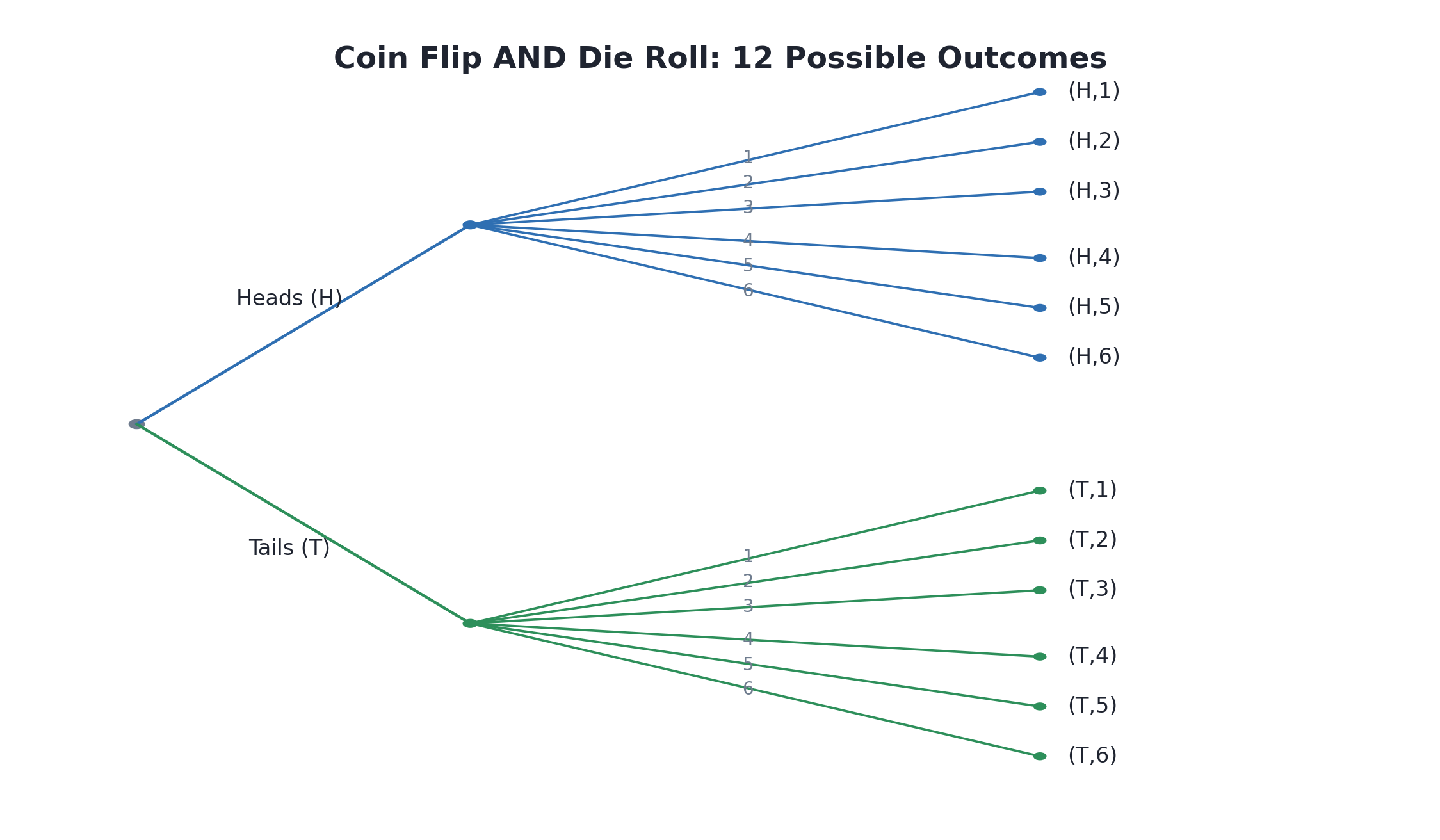
Why should we care about the distinction? Consider a simple event first. If you roll a single die, the sample space is just — that is outcomes. Easy to list, easy to count.
Now imagine a compound event: you roll that same die and flip a coin. The coin has outcomes and the die has , so the total number of outcome combinations is:
When a sample space is small, you might feel confident just listing combinations off the top of your head. But this casual approach hides two common pitfalls:
- Duplication — you accidentally count the same combination more than once.
- Omission — you skip a combination without realizing it.
Let's make this concrete. Imagine a restaurant offers appetizers and entrées. The total number of possible meals is . If you tried to scribble down every appetizer-entrée pair from memory, it would be surprisingly easy to miss one or repeat one — especially under time pressure. With combinations, even a careful person can lose track without a clear organizing structure.
Let's recap the key ideas from this lesson. A simple event involves a single stage or trial, while a compound event combines two or more stages whose outcomes pair together. Because the number of combined outcomes grows rapidly with each added stage, we need a systematic method to list them all without duplicating or missing any.
Up next, you will put these ideas into practice by identifying simple and compound events in real-world scenarios and explaining why an organized approach matters. Jump into the exercises and test how sharp your new perspective already is!