Welcome to the second lesson of our course on "The MLP Architecture: Activations & Initialization"! We're making excellent progress on our neural network journey. In the previous lesson, we successfully implemented a Multi-Layer Perceptron (MLP) by stacking multiple dense layers, allowing information to flow from input to output through our network.
Today, we'll be exploring an essential component of modern neural networks: the Rectified Linear Unit (ReLU) activation function. While we've been using the sigmoid activation function so far, ReLU has become the default activation function for most hidden layers in deep neural networks due to its computational efficiency and effectiveness in addressing the vanishing gradient problem.
By the end of this lesson, you'll understand what ReLU is, why it's so popular, and how to implement and incorporate it into your neural network architecture. We'll also modify our DenseLayer class to support different activation functions, making our neural network framework more flexible and powerful. Let's dive in!
Understanding Activation Functions and Their Importance
As we've seen in our previous work, activation functions introduce non-linearity into our neural networks. Without them, no matter how many layers we stack, our network would merely compute a linear transformation of the input data.
Let's quickly recall the sigmoid activation function we've been using:
function sigmoid(x) { return math.map(x, v => 1 / (1 + Math.exp(-v)));}
The sigmoid function maps any input to a value between 0 and 1, creating a smooth S-shaped curve. While it works well for certain tasks, sigmoid has some significant limitations:
Vanishing gradients: When inputs are very large or very small, the gradient of the sigmoid function becomes extremely small, slowing down learning. We'll be discussing gradients in much more detail in our next course about training neural networks, but for the time being, you can think of the gradient as the fundamental feedback signal that the network uses to adapt its weights and learn.
Computational expense: Computing exponentials is relatively expensive.
Not zero-centered: The output is always positive, which can cause zig-zagging dynamics during optimization.
These limitations become particularly problematic in deep networks with many layers. This is where alternative activation functions like ReLU come into play, offering solutions to many of these challenges.
The ReLU Activation Function
Implementing the ReLU Activation Function
Let's implement the ReLU activation function in JavaScript using mathjs. The implementation is simple, but to make it robust, we'll handle both numbers and arrays/matrices:
function relu(x) { if (typeof x === 'number') { return Math.max(0, x); } return math.map(x, v => Math.max(0, v));}
This function checks if the input x is a single number or an array/matrix. If it's a number, it simply returns the maximum of 0 and x. If it's an array or matrix, it uses mathjs's map function to apply the same operation element-wise. This ensures our relu function works efficiently for all input types we might encounter in our neural network.
Modifying Our DenseLayer for Different Activations
Now that we have both sigmoid and ReLU activation functions, let's modify our DenseLayer class to support different activation functions. This will make our neural network architecture more flexible. Here is the updated implementation:
The constructor takes an activationFnName parameter (defaulting to 'sigmoid' for backward compatibility).
The activation function is selected based on the provided name.
The forward method computes the weighted sum, adds the biases, and then applies the selected activation function.
The use of math.add(weightedSum, this.biases) ensures that biases are added correctly to the weighted sum, leveraging mathjs's broadcasting.
The forward method remains the same, but now it will use whichever activation function was selected during initialization.
Building an MLP with Mixed Activations
Examining ReLU Behavior with Different Inputs
Conclusion and Next Steps
Great work! You've now learned about the ReLU activation function, its advantages over sigmoid, and how to implement and use it in your neural network framework. You've also seen how to build MLPs with mixed activation functions and observed the unique behavior of ReLU in practice.
Up next, you'll get hands-on experience with a practice section focused on ReLU, where you'll solidify your understanding by applying what you've learned. After that, we'll move on to discuss activation functions specifically designed for output layers, such as linear and softmax activations, and see how they are used for different types of prediction tasks. Your neural network toolkit is expanding, and you're well on your way to building more flexible and powerful models!
Be a part of our community of 1M+ users who develop and demonstrate their skills on CodeSignal
JavaScript
function sigmoid(x) { return math.map(x, v => 1 / (1 + Math.exp(-v)));}
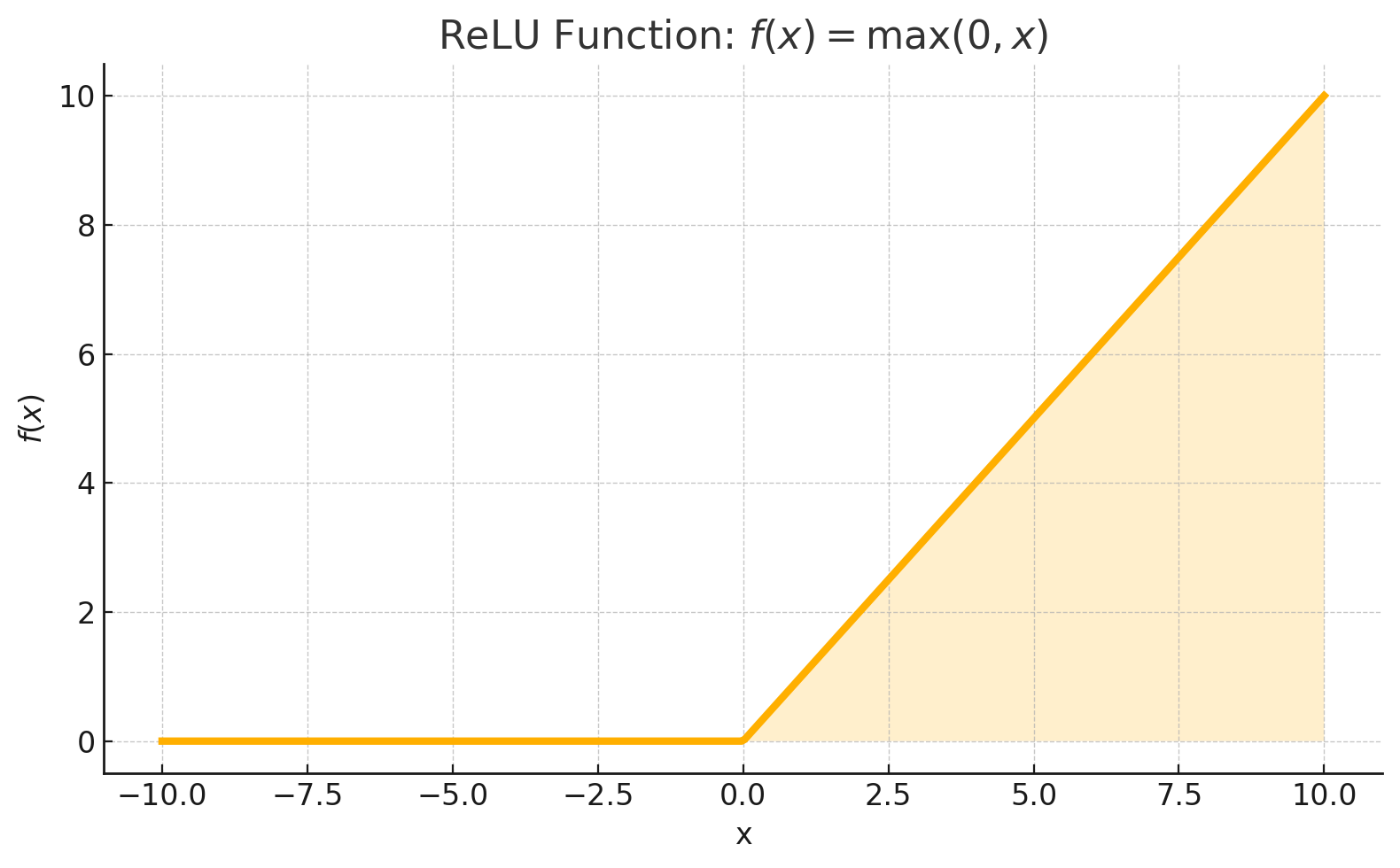
The Rectified Linear Unit (ReLU) is perhaps the simplest non-linear activation function, yet it has revolutionized deep learning. Its mathematical definition is elegantly straightforward:
f(x)=max(0,x)
In plain English: ReLU outputs the input directly if it's positive and outputs zero if the input is negative. This creates a simple "ramp" function that's linear for positive values and flat for negative values.
The advantages of ReLU over sigmoid are numerous and significant:
Computational efficiency: ReLU involves only a simple max operation, making it much faster to compute than functions involving exponentials.
Reduced vanishing gradient problem: For positive inputs, the gradient is always 1, allowing for much faster learning.
Sparsity: ReLU naturally creates sparse activations (many neurons output zero), which can be beneficial for representation learning.
Biological plausibility: The firing pattern of ReLU resembles that of biological neurons more closely than sigmoid.
These advantages have made ReLU the default choice for hidden layers in most modern neural networks. However, it's worth noting that ReLU also has a limitation known as the "dying ReLU problem" — neurons can get stuck in a state where they always output zero, effectively becoming "dead" and unable to learn.
JavaScript
function relu(x) { if (typeof x === 'number') { return Math.max(0, x); } return math.map(x, v => Math.max(0, v));}
With our enhanced DenseLayer class, we can now create an MLP that uses different activation functions for different layers. This is a common practice in deep learning, where ReLU is typically used for hidden layers and sigmoid (or other functions) for the output layer, depending on the task.
Let's create an MLP with ReLU for the first layer and sigmoid for the subsequent layers:
JavaScript
const math = require('mathjs');// Create a sample input as a mathjs matrixconst X_sample = math.matrix([[1.0, 0.5, -1.0, 2.0]]); // Shape [1, 4]console.log(`Input X (shape [${X_sample.size()[0]}, ${X_sample.size()[1]}]):\n`, X_sample.valueOf());// Create the MLP with different activation functionsconst mlp_relu = new MLP();mlp_relu.addLayer(new DenseLayer(4, 5, 'relu'));mlp_relu.addLayer(new DenseLayer(5, 3, 'sigmoid'));mlp_relu.addLayer(new DenseLayer(3, 1, 'sigmoid'));// Display information about our network architectureconsole.log(`\nMLP created with ${mlp_relu.layers.length} layers and mixed activations.`);mlp_relu.layers.forEach((layer, i) => { console.log(` Layer ${i + 1}: ${layer.nInputs} inputs, ${layer.nNeurons} neurons, Activation: ${layer.activationFnName}`);});
This creates a 3-layer MLP with:
A first layer using ReLU activation with 5 neurons
A second layer using sigmoid activation with 3 neurons
An output layer using sigmoid activation with 1 neuron
Let's see what happens when we forward propagate our input through this network with mixed activations:
JavaScript
// Forward propagate the input through the MLPconst output_relu = mlp_relu.forward(X_sample);console.log(`\nOutput of the MLP (shape [${output_relu.size()[0]}, ${output_relu.size()[1]}]):\n`, output_relu.valueOf());
This gives us:
Output of the MLP (shape [1, 1]): [ [ 0.52108506 ] ]
Our MLP with mixed activations is working! But to really understand how ReLU affects our network, let's try an input with mostly negative values:
// Create an input with mostly negative values as a mathjs matrixconst X_negative_heavy = math.matrix([[-1.0, -0.5, -2.0, -0.1]]);console.log(`\nInput with mostly negative values (shape [${X_negative_heavy.size()[0]}, ${X_negative_heavy.size()[1]}]):\n`, X_negative_heavy.valueOf());// Forward propagate and examine the first layer's outputconst output_negative_heavy = mlp_relu.forward(X_negative_heavy);console.log(`Output for negative heavy input (shape [${output_negative_heavy.size()[0]}, ${output_negative_heavy.size()[1]}]):\n`, output_negative_heavy.valueOf());console.log(`Output of first layer (ReLU) after forward pass:`, mlp_relu.layers[0].output.valueOf());
The result reveals a fascinating aspect of ReLU:
Input with mostly negative values (shape [1, 4]): [ [ -1, -0.5, -2, -0.1 ] ]Output for negative heavy input (shape [1, 1]): [ [ 0.5209758 ] ]Output of first layer (ReLU) after forward pass: [ [ 0, 0, 0, 0, 0 ] ]
Look at the output of the first layer! It's all zeros. This illustrates a key property of ReLU: it completely blocks negative inputs, resulting in a sparse activation pattern. In this case, all of our input values resulted in negative weighted sums in the first layer, so ReLU converted them all to zeros.
Despite this extreme first-layer output, our network still produced a non-zero final output. Why? Let's clarify with a concrete example:
Suppose the output of the first layer (after ReLU) is [0, 0, 0, 0, 0]. In the second layer, the weights are random numbers (for example, [0.2, -0.1, 0.05, 0.3, -0.2]), and let's assume the biases are all zeros for simplicity. The weighted sum for the next layer will be:
Passing this through the sigmoid activation gives:
sigmoid(0) = 0.5
So, even if all activations from the previous layer are zero and there is no bias, the output of the sigmoid neuron will be 0.5. This is why, in our example, the network can still produce a non-zero output even when the first layer outputs all zeros. If there are non-zero biases in the subsequent layers, the output can be different from 0.5, but with zero bias, the default output of the sigmoid is always 0.5.
A sigmoid output of 0.5 means the neuron is in its most "uncertain" state, right in the middle between its minimum (0) and maximum (1) possible outputs.
This example highlights the importance of proper weight initialization and careful network design when using ReLU. If too many neurons "die" (always output zero), the network's capacity to learn can be severely limited.
text
Output of the MLP (shape [1, 1]): [ [ 0.52108506 ] ]
JavaScript
// Create an input with mostly negative values as a mathjs matrixconst X_negative_heavy = math.matrix([[-1.0, -0.5, -2.0, -0.1]]);console.log(`\nInput with mostly negative values (shape [${X_negative_heavy.size()[0]}, ${X_negative_heavy.size()[1]}]):\n`, X_negative_heavy.valueOf());// Forward propagate and examine the first layer's outputconst output_negative_heavy = mlp_relu.forward(X_negative_heavy);console.log(`Output for negative heavy input (shape [${output_negative_heavy.size()[0]}, ${output_negative_heavy.size()[1]}]):\n`, output_negative_heavy.valueOf());console.log(`Output of first layer (ReLU) after forward pass:`, mlp_relu.layers[0].output.valueOf());
text
Input with mostly negative values (shape [1, 4]): [ [ -1, -0.5, -2, -0.1 ] ]Output for negative heavy input (shape [1, 1]): [ [ 0.5209758 ] ]Output of first layer (ReLU) after forward pass: [ [ 0, 0, 0, 0, 0 ] ]