Hello there! Welcome to the first lesson of our course "Sequence Models & The Dawn of Attention". This initial lesson marks the beginning of an exciting journey that will take us from traditional sequence modeling approaches all the way to the cutting-edge Transformer architecture that powers today's most advanced AI systems.
Before we dive into our exploration of sequence models, let's establish what we expect you to bring to this course path. We assume you have solid foundations in Python programming, basic machine learning concepts, and PyTorch fundamentals, including tensor operations and neural network construction. Familiarity with basic linear algebra and calculus will also serve you well as we work through mathematical concepts.
Our learning path consists of four comprehensive courses designed to give you deep expertise in Transformer architectures. In this first Course, we'll explore why traditional RNNs and LSTMs struggle with long sequences and build attention mechanisms from scratch, mastering the query-key-value paradigm. Next, in Course 2 we'll systematically construct the complete Transformer architecture, creating reusable components such as multi-head attention modules, feed-forward networks, and positional encodings. By Course 3 we'll be able to combine everything into a complete Transformer model, implementing autoregressive training with teacher forcing and exploring different decoding and inference strategies. Finally, in the last Course we'll harness the powerful Hugging Face ecosystem to work with pre-trained models and fine-tune them for real-world applications.
By the end of this path, you'll have gained a profound understanding of how Transformers work under the hood and the practical skills to apply them effectively. Today, in our first lesson, we begin by revisiting sequence models to understand their limitations and why the AI community needed something better. Let's get started!
Sequential data surrounds us everywhere: the words in this sentence follow a specific order, stock prices change over time, and DNA sequences encode genetic information through their arrangement. Traditional feedforward neural networks process each input independently, but sequence modeling requires understanding how current elements relate to previous ones.
The challenge lies in temporal dependencies: understanding that "the cat sat on the" should be followed by something like "mat" requires remembering context from earlier in the sequence. Early approaches like n-grams could only look back a fixed number of steps, severely limiting their ability to capture long-range relationships. This limitation sparked the development of recurrent architectures that could theoretically maintain information across arbitrary sequence lengths.
However, as we'll discover today, even sophisticated recurrent models face fundamental challenges when sequences grow long. This limitation will motivate the development of attention mechanisms and, later, of the Transformer architecture.
Now, let's examine the specific challenge we'll use to demonstrate sequence model limitations. Our task involves predicting the first element of a sequence based on observing the entire sequence, which creates a long-range dependency problem as sequences grow longer:
This function creates our experimental setup. We generate random sequences of specified lengths, where each sequence contains real-valued numbers. The crucial aspect is that our target is always the very first element of each sequence; that is, as sequences get longer, the model must remember this initial value while processing many intervening elements.
Notice the tensor shapes: sequences has dimensions (num_samples, seq_length, 1), representing batch size, sequence length, and feature dimension. The targets tensor becomes (num_samples, 1) after we extract and reshape the first elements. This structure follows standard NLP conventions, where we often work with three-dimensional tensors for sequential data.
Our LSTM implementation follows PyTorch conventions while keeping the architecture simple enough to clearly observe performance patterns across different sequence lengths:
Our model architecture consists of a single LSTM layer followed by a linear output layer. The batch_first=True parameter ensures our input tensors follow the (batch, sequence, features) convention. We initialize hidden and cell states to zeros for each forward pass, giving each sequence a fresh start.
The key decision here is using out[:, -1, :], that is, we only use the final time step's hidden state for prediction. This forces the LSTM to compress all relevant information from the entire sequence into this final hidden state, creating the exact challenge we want to study.
Our training function implements a standard supervised learning loop optimized for observing performance degradation patterns.
We use Mean Squared Error as our loss function since we're predicting continuous values. The Adam optimizer provides stable convergence with a learning rate that works well across different sequence lengths. After training, we evaluate the model one final time with gradients disabled to get a clean measure of final performance.
The function returns the final loss value, which serves as our metric for comparing performance across different sequence lengths. Higher loss values indicate the model struggles more with that particular sequence length.
Now we can systematically test how LSTM performance degrades as sequences grow longer, revealing the fundamental limitations we'll address with attention mechanisms.
Our experiment systematically tests sequence lengths from 5 to 100 elements. For each length, we create fresh data according to the current seq_len, as well as a new model to ensure a fair comparison. The results reveal a clear pattern:
The pattern is striking: performance remains strong for very short sequences but degrades substantially as sequences grow longer, with significant deterioration evident beyond length 10. We can also plot these values to make this trend even clearer:
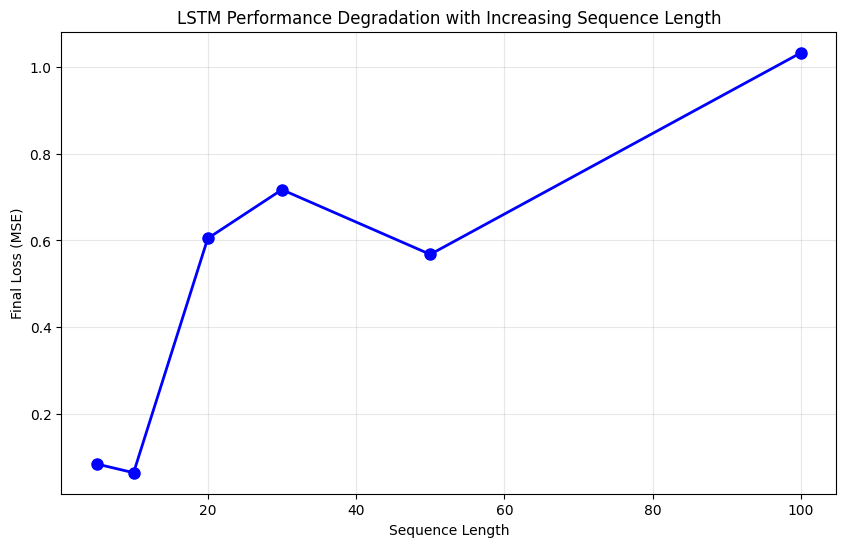
This performance degradation demonstrates the long-range dependency problem that motivated the development of attention mechanisms: despite LSTMs' theoretical ability to maintain long-term memory, practical limitations emerge when sequences grow beyond certain lengths.
Today, we revisited the foundations of sequence modeling and observed firsthand why RNNs and LSTMs, despite their innovations, face fundamental challenges with long sequences. The experiment we conducted demonstrates how even sophisticated gating mechanisms struggle to maintain relevant information across extended sequences. This limitation isn't merely academic — it affects real-world applications where understanding long-range dependencies is crucial, from document comprehension to protein sequence analysis.
The degradation we observed motivates the need for alternative architectures that can efficiently connect distant elements in sequences. In our next lesson, we'll begin exploring attention mechanisms: the breakthrough that addresses these limitations by allowing models to directly access any position in a sequence. This innovation will pave our way toward understanding the Transformer architecture that revolutionized modern AI. But now, it's time for some practice!
