This course was developed in partnership with Amazon and AWS.
Welcome to the first lesson of our course on machine learning fundamentals. As experienced practitioners, you're likely familiar with most of these concepts, but let's take a moment to revisit the essential first steps of any ML project. Before diving into more advanced topics and cloud-based tools like Amazon SageMaker, it's worth reinforcing these foundational practices that often determine the success of your models.
In this lesson, we'll walk through loading a real-world dataset, exploring its structure, and visualizing key patterns. While these may seem like routine tasks, they're critical for making informed decisions during preprocessing and model selection, whether you're working locally or deploying to the cloud.
We'll be working with the California housing dataset — a classic choice for regression tasks that you've probably encountered before. This dataset contains district-level information including median house values, average room counts, and population data.
The California housing dataset was originally constructed from the 1990 U.S. Census and provides a snapshot of housing characteristics across thousands of California neighborhoods. Each row represents a district, with features describing socioeconomic and geographic attributes such as median income, average number of rooms and bedrooms, population, and latitude/longitude. The primary objective with this dataset is to predict the median house value for each district, making it a practical benchmark for regression modeling and feature exploration.
As usual, we'll use pandas for data manipulation. In the CodeSignal coding environment for these practice exercises, all the necessary libraries are already pre-installed, so you can start coding right away.
The data loads into a pandas DataFrame — the workhorse data structure you're undoubtedly familiar with for tabular data manipulation in Python.
Now that we have our data loaded, let's start by understanding its basic structure. The first question we need to answer is: how much data are we working with?
This tells us we're working with 20,640 samples across 9 columns — a reasonably sized dataset for our purposes:
With the dimensions established, let's dive deeper into the structure of our features. Understanding data types is crucial for determining appropriate preprocessing steps and identifying potential issues early.
Here's what we see:
All features are numeric (float64), which simplifies our preprocessing pipeline. Notice also that all columns show the same non-null count as our total rows — a good initial sign for data quality.
The schema gives us the structure, but let's see what the actual data looks like to get a concrete understanding of our features:
This gives us a concrete view of what our data looks like:
The values look reasonable — we can see geographic coordinates (Latitude/Longitude), housing characteristics (rooms, age), and our target variable (MedHouseVal). Note that MedHouseVal is scaled in units of $100,000, so a value of 4.526 represents $452,600. Now let's get a statistical overview of these features.
Moving beyond individual data points, let's examine the overall distribution and characteristics of our features. To ensure we can see all columns clearly in our output, we'll first adjust pandas display settings:
The pd.set_option('display.max_columns', None) command ensures that pandas displays all columns in our output rather than truncating them with ellipses (...) when there are many features. This is particularly useful for wide datasets where we want to see the complete statistical summary.
The results reveal some interesting patterns:
Notice the extreme outliers in several features:
- AveOccup: Maximum of 1,243.33 people per household (clearly unrealistic)
- AveRooms: Maximum of 141.91 rooms per household (also unrealistic)
- AveBedrms: Maximum of 34.07 bedrooms per household (highly unusual)
- Population: Maximum of 35,682 in a single district (extremely high)
These outliers will need to be addressed during preprocessing. The geographic coordinates confirm we're dealing with California data, and the target variable shows a reasonable range of house values with a sharp spike at the maximum.
While our initial schema inspection suggested complete data, let's explicitly verify there are no missing values that could complicate our analysis:
Fortunately, we have a clean dataset with no missing values across any features:
This is always a pleasant surprise, though not always the reality in production environments. With clean, complete data, we can move directly to visualization without worrying about imputation strategies.
While summary statistics are informative, visualizations often reveal patterns that numbers alone miss. Let's create two key visualizations to understand our target variable and feature relationships:
For feature relationships, a correlation heatmap provides a quick overview of linear dependencies:
Now let's display both visualizations:
The resulting plots provide valuable insights into our dataset:
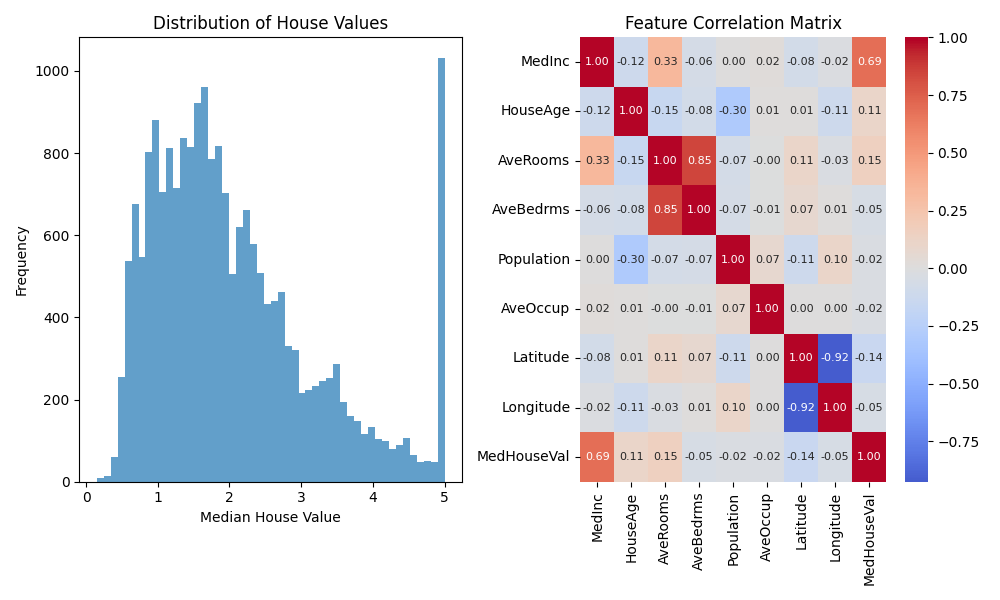
Left Plot – Distribution of House Values: The histogram illustrates that most homes in the dataset have relatively low median values, primarily between $100,000 and $200,000. The distribution is right-skewed, meaning there are many affordable homes and progressively fewer expensive ones as values increase. Notably, there is a sharp spike at the maximum value, indicating that the data is capped at the high end—so the highest house values are likely limited by the dataset rather than natural occurrence. This is an important consideration when building models, as it may impact predictions for high-value properties.
Right Plot – Feature Correlation Matrix: The heatmap displays the pairwise correlations between the dataset's features. Here are some key observations:
- Median Income (
MedInc) has the strongest positive correlation with median house value (MedHouseVal), at 0.69. This means higher-income neighborhoods tend to have higher house values—making income a crucial predictive feature. - Latitude shows a weak negative correlation (-0.14) with house values, hinting at mild geographic trends (such as homes in certain regions tending to cost more or less).
- Average Rooms (
AveRooms) and Average Bedrooms (AveBedrms) have a very high correlation (0.85), reflecting that these features move closely together. - Population and Average Occupancy both show very weak correlations with house value, indicating they are likely less important predictors.
These findings help us decide which features to prioritize, which to potentially remove or combine, and remind us to be cautious when interpreting predictions for homes at the upper value cap.
We've just walked through the fundamental EDA workflow: data loading, structural inspection, statistical summarization, and basic visualization. While these steps might feel routine, they're the foundation that informs every subsequent decision in your ML pipeline.
These practices become even more critical when working with unfamiliar datasets or when transitioning between local development and cloud deployment. The insights gained here directly influence your preprocessing strategies, feature engineering decisions, and model selection.
In the upcoming exercises, you'll apply these techniques hands-on. Remember, thorough data understanding at this stage saves significant debugging time later and often reveals opportunities for performance improvements that sophisticated algorithms alone cannot provide.
