Welcome back to our course Neural Network Fundamentals: Neurons and Layers! In this third lesson, we're building upon what you learned in our previous lesson about the basic artificial neuron. You've already implemented a simple neuron that computes a weighted sum of inputs plus a bias.
Today, we're taking an important step forward by introducing activation functions — a crucial component that enables neural networks to learn complex patterns. In particular, we'll focus on the Sigmoid activation function, one of the classical functions used in neural networks.
In our previous lesson, our neuron could only produce linear outputs. While this is useful for some tasks, it severely limits what our neural networks can learn. Today, we'll overcome this limitation by adding non-linearity to our neurons, allowing them to model more complex relationships in data.
The Need for Non-Linearity
Understanding Activation Functions
An activation function determines whether a neuron should be "activated" or not, based on the weighted sum of its inputs.
In biological terms, this mimics how neurons in our brains "fire" when stimulated sufficiently. In computational terms, activation functions introduce non-linearity into the network, allowing it to learn complex patterns.
Activation functions typically have these characteristics:
They are non-linear, allowing the network to model complex relationships.
They are differentiable, which is important for the training process (we'll explore this in future lessons).
They usually map inputs to a bounded range (like [0,1] or [-1,1]).
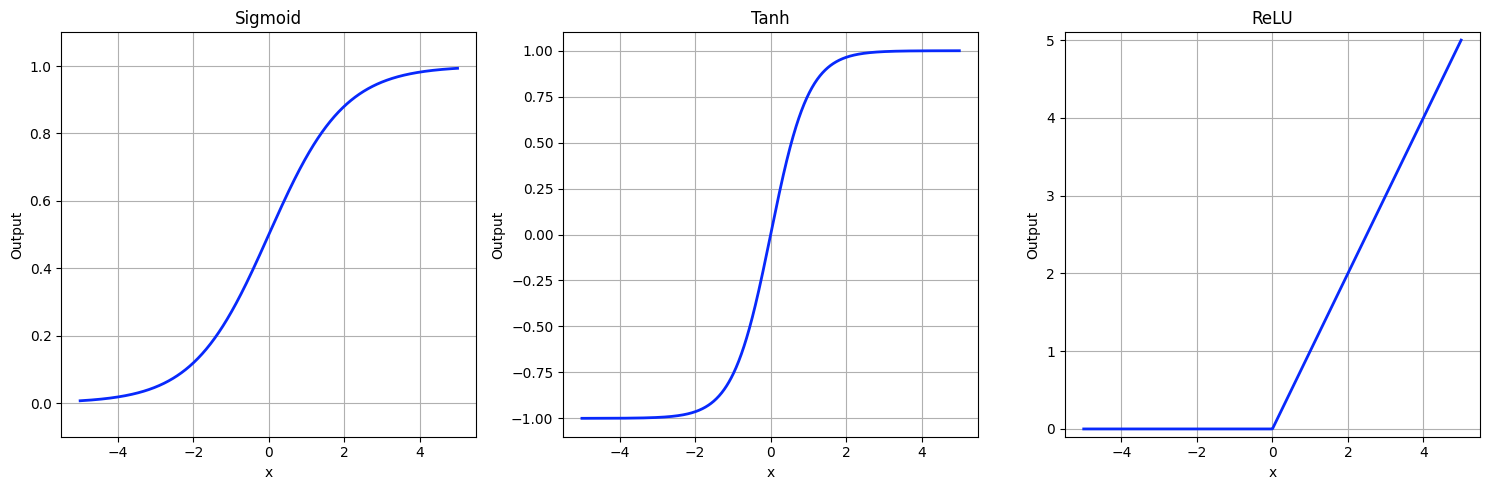
Some common activation functions include:
Sigmoid: Maps inputs to values between 0 and 1.
Tanh: Maps inputs to values between -1 and 1.
ReLU (Rectified Linear Unit): Returns the input if positive; otherwise, returns 0.
Here is the visualization of neural network activation functions:
In this lesson, we'll focus on implementing and using the Sigmoid function, which was historically one of the first activation functions used in neural networks.
Join the 1M+ learners on CodeSignal
Be a part of our community of 1M+ users who develop and demonstrate their skills on CodeSignal
Before diving into specific activation functions, let's understand why we need them in the first place.
The neuron we built in the previous lesson computes a weighted sum of inputs plus a bias. This is a linear transformation — mathematically, it can only represent straight lines (in 2D) or flat planes (in higher dimensions).
Consider what would happen if we stacked multiple layers of these linear neurons:
Layer 1's output is a linear function of the input:
Layer1out=W1X+b1
Layer 2's output is a linear function of Layer 1's output:
We can define new parameters W3=(W2W1) and b3=(W2b1+b2), so:
Layer2out=W3X+b3
As we can see, this simplifies to just another linear function! No matter how many linear layers we stack, the entire network would still only be able to learn linear relationships.
But real-world problems are rarely linear. Think about image recognition — the relationship between pixel values and whether an image contains a cat is highly non-linear. To model such complex patterns, we need to introduce non-linearity into our networks.
This is precisely the role of activation functions — they apply a non-linear transformation to the neuron's output, enabling neural networks to learn and represent more complex patterns.
The Sigmoid Activation Function
Implementing the Sigmoid Function
Now, let's implement the sigmoid function in JavaScript using the mathjs library. We'll use math.map to handle both numbers and arrays, and use JavaScript's Math.exp for exponentials.
const math = require('mathjs');/** * Sigmoid activation function. * x: A number or an array of numbers. * Returns the sigmoid of x. */function sigmoid(x) { // Use math.map to handle both numbers and arrays return math.map(x, v => 1 / (1 + Math.exp(-v)));}
This implementation uses math.map, which applies the function to each element if x is an array, or directly if x is a single number. This makes the function flexible and concise.
Let's test this function with a few values to make sure it works as expected:
console.log(`sigmoid(0) = ${sigmoid(0)}`); // Should be 0.5console.log(`sigmoid(2) = ${sigmoid(2).toFixed(4)}`); // Should be around 0.88console.log(`sigmoid(-2) = ${sigmoid(-2).toFixed(4)}`); // Should be around 0.12console.log(`sigmoid([-2, 0, 2]) = [${sigmoid([-2, 0, 2]).map(v => v.toFixed(4)).join(', ')}]`);
When you run this code, you'll see that our sigmoid function correctly maps the input values to their corresponding sigmoid outputs, demonstrating both its behavior for individual values and its ability to process arrays.
Enhancing Our Neuron with Activation
Testing the Activated Neuron
Now let's test our enhanced neuron to see how the activation function affects its output:
if (require.main === module) { const numInputFeatures = 3; const neuron = new Neuron(numInputFeatures); const sampleInputs = [1.0, 2.0, 3.0]; console.log(`\nInput to neuron: [${sampleInputs.join(', ')}]`); const [activatedOutput, rawOutput] = neuron.forward(sampleInputs); console.log(`Neuron's raw output (weighted sum + bias): ${rawOutput.toFixed(4)}`); console.log(`Neuron's activated output (Sigmoid): ${activatedOutput.toFixed(4)}`);}
When you run this code, you'll observe:
The random weights and bias of our initialized neuron.
The input values we're feeding into the neuron.
The raw output (weighted sum + bias) before applying the activation function.
The final activated output after applying the sigmoid function.
The key insight here is seeing how the sigmoid function transforms the raw output. If the raw output is a large positive number, the sigmoid output will be close to 1. If the raw output is a large negative number, the sigmoid output will be close to 0. And if the raw output is around 0, the sigmoid output will be around 0.5.
This non-linear transformation is what enables neural networks to model complex patterns and make decisions. The sigmoid function essentially "squashes" the raw output into a range between 0 and 1, which can be interpreted as a probability or a level of activation.
Conclusion and Next Steps
Excellent work! You've enhanced your neuron by adding the sigmoid activation function, introducing the critical non-linearity that neural networks need to model complex patterns. We've explored why non-linearity is essential, how the sigmoid function works mathematically, and how to implement it efficiently in code. This foundational understanding of activation functions is vital as you continue your journey into neural networks.
In the upcoming practice section, you'll gain hands-on experience working with activation functions and observe their effects on various inputs. After mastering the concepts in this lesson, we'll move forward by combining multiple neurons into layers, creating more sophisticated neural network architectures that can solve increasingly complex problems. Keep up the great work!
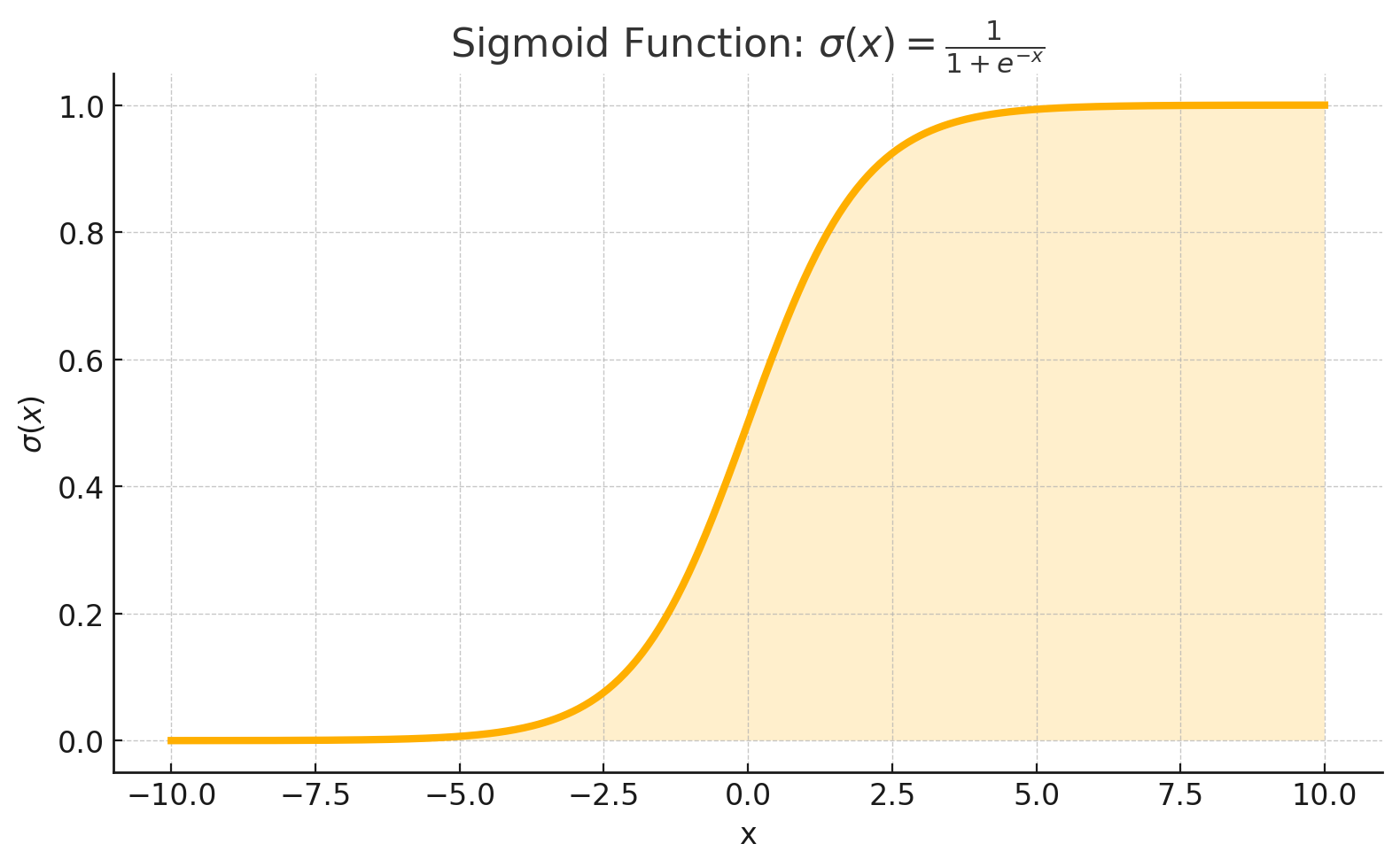
The Sigmoid (also called the logistic function) maps any input value to a value between 0 and 1. It's defined by the following formula:
sigmoid(x)=1+e−x1
Where e is the base of the natural logarithm.
The Sigmoid function has several interesting properties:
It's S-shaped (hence the name "sigmoid," meaning S-shaped).
For large positive inputs, it approaches 1, while for large negative inputs, it approaches 0.
It has a smooth gradient, making it suitable for gradient-based learning algorithms.
Its output can be interpreted as a probability (since it's between 0 and 1).
Let's visualize this function with a graph:
JavaScript
const math = require('mathjs');/** * Sigmoid activation function. * x: A number or an array of numbers. * Returns the sigmoid of x. */function sigmoid(x) { // Use math.map to handle both numbers and arrays return math.map(x, v => 1 / (1 + Math.exp(-v)));}
JavaScript
console.log(`sigmoid(0) = ${sigmoid(0)}`); // Should be 0.5console.log(`sigmoid(2) = ${sigmoid(2).toFixed(4)}`); // Should be around 0.88console.log(`sigmoid(-2) = ${sigmoid(-2).toFixed(4)}`); // Should be around 0.12console.log(`sigmoid([-2, 0, 2]) = [${sigmoid([-2, 0, 2]).map(v => v.toFixed(4)).join(', ')}]`);
Now that we have our sigmoid function, let's enhance our Neuron class from the previous lesson to include this activation function. We'll modify the forward method to apply the sigmoid function to the weighted sum.
Here's how the updated Neuron class looks in JavaScript, using mathjs for dot products and exponentials:
JavaScript
const math = require('mathjs');/** * Sigmoid activation function. * x: A number or an array of numbers. * Returns the sigmoid of x. */function sigmoid(x) { // Use math.map to handle both numbers and arrays return math.map(x, v => 1 / (1 + Math.exp(-v)));}class Neuron { /** * Initialize a neuron. * nInputs: Number of input features. */ constructor(nInputs) { this.weights = math.multiply(math.random([nInputs]), 0.1); // Small random weights this.bias = 0.0; console.log(`Neuron initialized with ${nInputs} inputs.`); console.log(`Initial weights: [${this.weights.map(w => w.toFixed(4)).join(', ')}]`); console.log(`Initial bias: ${this.bias}`); } /** * Calculate the neuron's output: * 1. Weighted sum of inputs and weights, plus bias. * 2. Apply the sigmoid activation function. * inputs: An array of input features (must match nInputs). * Returns: [activatedOutput, rawOutput] */ forward(inputs) { if (inputs.length !== this.weights.length) { throw new Error( `Input size ${inputs.length} does not match neuron's expected input size ${this.weights.length}.` ); } // Calculate the weighted sum: dot product of inputs and weights const weightedSum = math.dot(inputs, this.weights); // Add bias const rawOutput = weightedSum + this.bias; // Apply activation function const activatedOutput = sigmoid([rawOutput])[0]; return [activatedOutput, rawOutput]; }}
The key changes in this updated version are:
We still calculate the weighted sum and add the bias, but now we call this intermediate result rawOutput.
We apply the sigmoid function to the raw output, producing an activatedOutput.
We return both the activated output and the raw output, which will help us understand the effect of the activation function.
This two-step process — first calculating the linear combination and then applying the non-linear activation — is fundamental to how neurons operate in neural networks.
JavaScript
if (require.main === module) { const numInputFeatures = 3; const neuron = new Neuron(numInputFeatures); const sampleInputs = [1.0, 2.0, 3.0]; console.log(`\nInput to neuron: [${sampleInputs.join(', ')}]`); const [activatedOutput, rawOutput] = neuron.forward(sampleInputs); console.log(`Neuron's raw output (weighted sum + bias): ${rawOutput.toFixed(4)}`); console.log(`Neuron's activated output (Sigmoid): ${activatedOutput.toFixed(4)}`);}
 In this lesson, we'll focus on implementing and using the Sigmoid function, which was historically one of the first activation functions used in neural networks.
In this lesson, we'll focus on implementing and using the Sigmoid function, which was historically one of the first activation functions used in neural networks.