Welcome to the final lesson of the "Foundations of NLP Data Processing" course! So far, you've explored various techniques for representing text as numerical data, including Bag-of-Words and TF-IDF. While these methods are useful, they have a major limitation: they treat words as independent tokens without capturing their meanings or relationships.
In this lesson, we introduce word embeddings, a powerful approach to representing words as continuous-valued vectors that encode semantic meaning. Word embeddings allow models to understand relationships between words based on their context in large text corpora. Unlike traditional text representations, embeddings can capture synonymy, analogies, and contextual similarities.
Before diving into code, let's build an intuition for word embeddings by examining some limitations of traditional approaches:
-
Bag-of-Words (BoW) and TF-IDF ignore meaning
- In BoW and TF-IDF, words are represented as isolated units. Two words with similar meanings (e.g., "king" and "queen") have no direct relationship in these models.
- Example:
- "I love NLP" →
[1, 1, 1, 0, 0] - "I enjoy NLP" →
[1, 0, 1, 1, 0] - These two sentences are similar in meaning, but their vector representations don't capture this!
- "I love NLP" →
-
Word Order Matters
- "The cat chased the dog" vs. "The dog chased the cat" have different meanings, but traditional models treat them similarly.
-
No Concept of Context
- "Apple" (the fruit) and "Apple" (the company) are treated the same.
Word embeddings solve these issues by representing words as dense vectors in a multi-dimensional space, where words with similar meanings have closer representations.
Word embeddings are generated by training models on large text data. The key idea is:
- Words appearing in similar contexts should have similar vector representations.
- Example: The words "king" and "queen" often appear in similar contexts (e.g., "the king rules the kingdom," "the queen rules the kingdom").
- Models like Word2Vec and GloVe learn to place these words closer together in the vector space.
There are different approaches to training word embeddings:
- Continuous Bag of Words (CBOW): Predicts a word based on surrounding words.
- Skip-gram: Predicts surrounding words given a target word.
- GloVe (Global Vectors for Word Representation): Utilizes word co-occurrence statistics from a corpus.
- Word2Vec: Developed by Google, it uses either the CBOW or Skip-gram approach. It focuses on predicting a word based on its context or vice versa, which makes it efficient for capturing local context.
- GloVe: Developed by Stanford, it uses global word co-occurrence statistics to learn embeddings. This approach captures both local and global context, making it effective for understanding broader semantic relationships.
Instead of training from scratch, we can use pre-trained embeddings. Here, we'll use a smaller GloVe model (25-dimensional) for demonstration, but you can easily switch to other models like Word2Vec or FastText depending on your needs. If you want to suppress the output during model loading, you can use the following approach:
To suppress the output during model loading, you need to import the os and contextlib modules. The os.devnull is used to discard any output, while contextlib.redirect_stdout and contextlib.redirect_stderr are used to redirect standard output and error streams to os.devnull. This way, the model loads silently without printing any messages to the console.
While pre-trained models are powerful, there are scenarios where training a custom word embedding model might be beneficial:
- Domain-Specific Vocabulary: If your text data contains specialized vocabulary not well-represented in general corpora, a custom model can better capture these nuances.
- Language Variants: For dialects or less common languages, pre-trained models may not be available or effective.
- Updated Contexts: If your data reflects recent trends or changes in language use, a custom model can capture these shifts.
To understand the learned embeddings, we can visualize them using Principal Component Analysis (PCA), which reduces the high-dimensional vectors to 2D space:
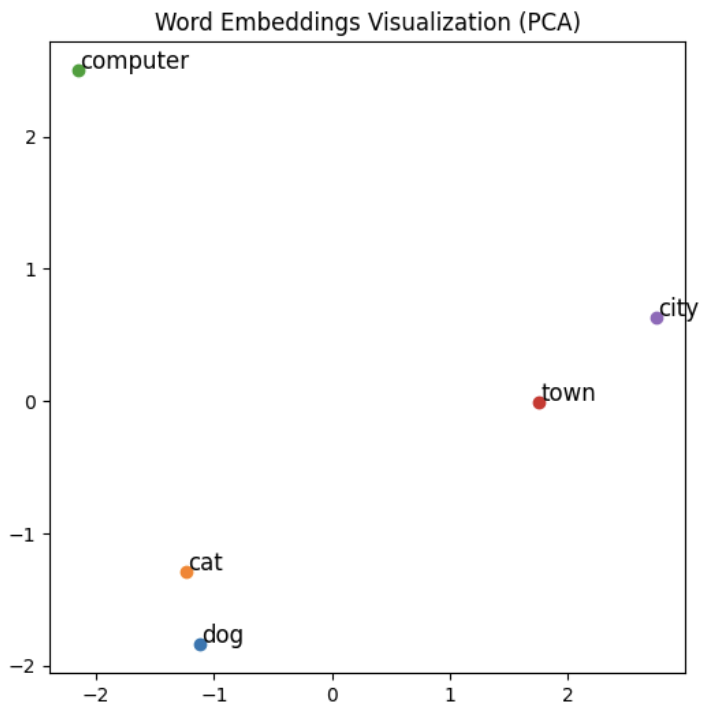
This visualization helps us see how similar words are grouped together in the vector space. For instance, we can see that "cat" and "dog" are close to each other, as are "city" and "town," while "computer" is positioned further away, indicating its distinct semantic meaning compared to the other words.
Word embeddings capture the meaning of words based on their context, with models like Word2Vec and GloVe learning these embeddings by predicting words from their neighbors or using co-occurrence statistics. Pre-trained embeddings offer efficient word representation, and visualization aids in understanding word relationships. Moving forward, experiment with different datasets, explore models like GloVe and FastText, and apply word embeddings in NLP tasks such as sentiment analysis and text classification.
