This course was developed in conjunction with Amazon and AWS.
Welcome to the first lesson of this course on prompt engineering. In this lesson, I will introduce a key principle behind how large language models (LLMs) generate text. Understanding this principle is important because it will help you write better prompts and get more accurate and helpful responses from LLMs.
LLMs, like the ones you will use in this course, generate text by predicting one piece at a time. These pieces are called tokens. The model looks at the text you have already given (the context) and tries to guess what comes next, one token at a time. This process is repeated until the model finishes its response.
Let's break down what a token is and how this prediction process works.
A token is a small chunk of text. Depending on the language model, it can be a word, part of a word, or even just a character. LLMs do not see text as whole sentences or paragraphs. Instead, they break everything down into tokens.
For example, let's look at the phrase:
Depending on the model, this might be split into tokens like:
Abottleofwater
Or, in some cases, bottle might be split into bott and le if the model uses smaller pieces. For this lesson, you can think of tokens as words or short word parts.
Tokens are important because the model predicts text one token, not one word or sentence at a time.
Now, let's see how LLMs generate text step by step. The model always looks at the context — the already written tokens — and predicts what comes next.
Let's start with a simple prompt:
At this point, the model has three tokens: A, bottle, and of. It now needs to predict the next token. The model looks at the context (A bottle of) and tries to guess what is most likely to come next.
Common next tokens might be:
waterwinemilk
The model chooses the most likely one based on its training. If you continue, the process repeats. For example, if the model predicts water, the new context is:
Now, the model can predict what comes after water, such as a period or another word.
This process — predicting one token at a time — continues until the model decides the response is complete.
The context, or the tokens that come before, is very important. It changes what the model predicts next. Let's look at two examples to see how context affects the prediction.
First example:
Possible next tokens: water, wine, milk, etc.
Now, let's add more context:
Here, the model is more likely to predict bread as the next token because "a loaf of bread" is a common phrase, especially after milk.
Another example:
Possible next tokens: mat, sofa, floor, etc.
But if we change the context:
Now, the model might predict mouse, dog, or ball as the next token.
As you can see, the tokens that come before (the context) guide the model's predictions. This is why thinking about how you phrase your prompts is important.
Modern chat interfaces make it easy to use LLMs as assistants. While LLMs always predict the next token, chat interfaces add instructions or context to guide the model in acting helpfully and following your requests.
For example, when you type a question or instruction, the chat interface may add a hidden prompt like "You are a helpful assistant." This tells the LLM to answer your question, follow your instructions, and continue your text.
The chat interface also keeps track of the conversation history so the LLM can give more relevant and coherent responses. This setup allows you to interact with LLMs naturally, as if chatting with an assistant.
During practice, you will work with LibreChat – an application that allows you to chat with various LLMs. In our environment, you can chat with AWS Bedrock models. You can switch the model, which will be required in some practices. The interface is straightforward: send a message and get a response.
Note:
Entersends a messageShift + Enteradds a newline to the text message
You can also open a sidebar to access additional settings.
If anything goes wrong or you want to start the practice over, use the Reset button in the bottom right corner:
In the sidebar, you can see your chat history and create a new chat. Note: in practice, Cosmo will evaluate the entire chat history when checking your solution, paying close attention to the latest chat.
Also, you can access the application settings by clicking on Cosmo. In the application settings, you can change the theme from light to dark, set the preferred interface language, switch controls, and more!
You can manage a chat by clicking on three dots near its name.
Use it to delete chats where you experimented with prompts or received intermediate results, so Cosmo doesn't take them into account.
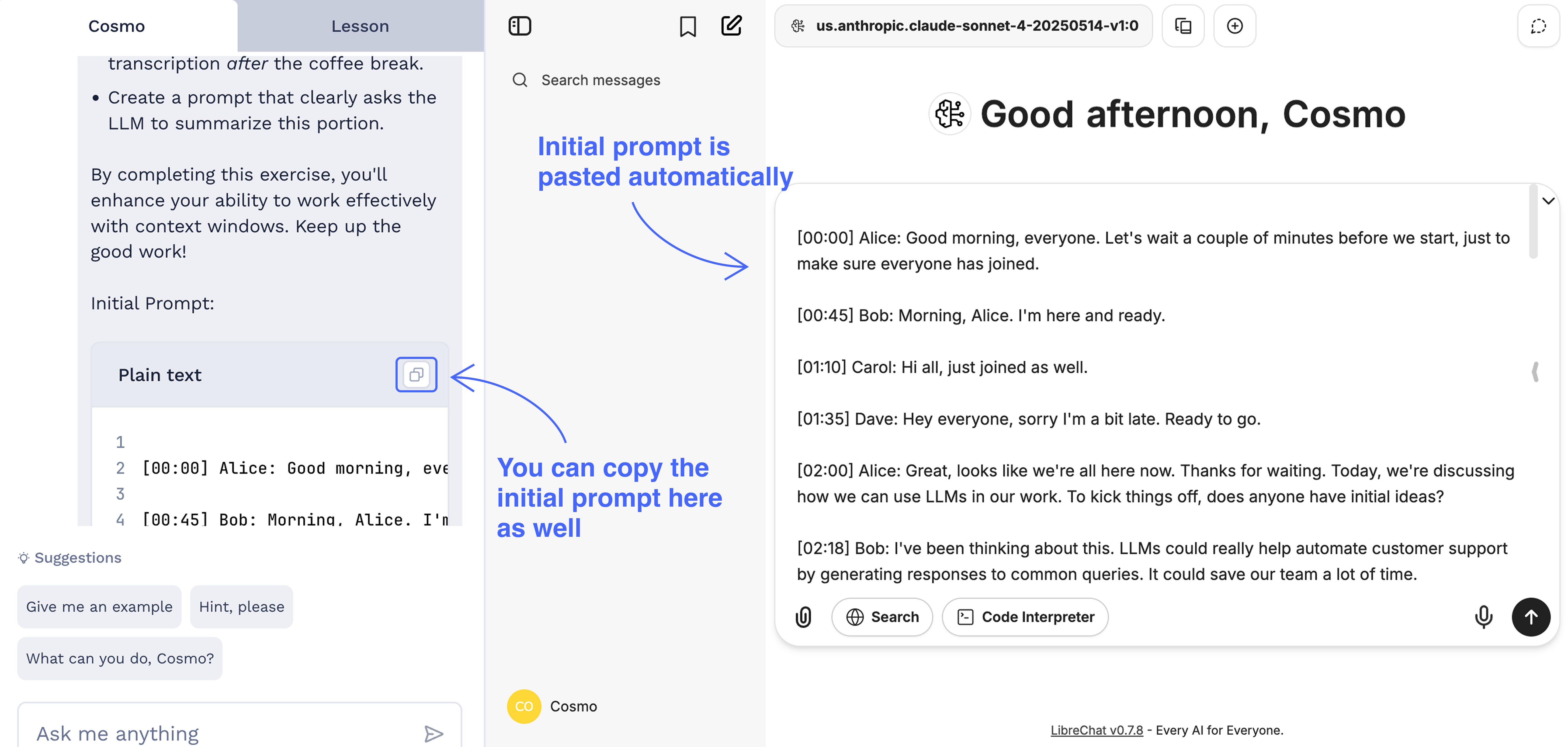
Some practices require working with some initial prompt that you will be asked to modify, enhance or adjust. Initial prompt is pasted automatically in the chat. If you accidentally remove it or it doesn't load for any reason, you can always find the full initial prompt in the task description. Just click the copy button and paste it in the chat!
In this lesson, you learned that LLMs generate text by predicting one token at a time, always using the context of what has come before. You saw how the choice of context can change what the model predicts next. Understanding this process is the first step to writing better prompts and getting more useful responses from LLMs.
Next, you will get a chance to practice these ideas. You will try different prompts and see how changing the context changes the model's predictions. This hands-on practice will help you become more comfortable with how LLMs work and how to guide them with your prompts.
